Slowly Changing Dimension
The Slowly Changing Dimension processor generates updates to a Type 1 or Type 2 slowly changing dimension by evaluating change data against master dimension data. Use the processor in a pipeline to update slowly changing dimension data stored in a database table or a set of files.
When you configure a Slowly Changing Dimension processor, you specify the slowly changing dimension type and the key fields used to match change and master data.
You can specify the action to take when a change record includes fields not included in the master records. You can replace null values in change data with corresponding master data. You can also include all master data in the processor output so the destination can overwrite file dimensions as needed.
You can specify one or more tracking fields and configure the tracking type for the fields. You can also specify a subset of fields to trigger a Type 2 change.
When you configure a slowly changing dimension pipeline it's important to configure pipeline properties and all stage properties appropriately for your use case. For more information, see Pipeline Configuration.
Slowly Changing Dimension Pipeline
A slowly changing dimension pipeline compares change data against master dimension data, then writes the changes to the master dimension data.
A slowly changing dimension pipeline can process a traditional table dimension, where the dimension data is stored in a database table. It can also process a file dimension, where the dimension data is stored in a set of files in a directory.
The simplest slowly changing dimension pipeline looks like this:
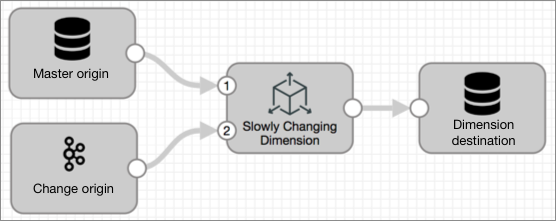
- Master origin - Reads the master dimension data. Use one of the following
origins:
- Whole Directory - Use to read a file dimension. The dimension files must reside within a single directory, but can include partitions. No non-dimension files should exist in the directory.
- JDBC Table origin - Use to read a table dimension.
- Change origin - Reads change data. Change data can be read by any Transformer origin.
- Slowly Changing Dimension processor - Compares change data against master data and flags change records for insert or update.
- Dimension destination - Writes results to the master
dimension. Use one of the following destinations:
- ADLS Gen1 - Use to write to a file dimension on Azure Data Lake Storage Gen1.
- ADLS Gen2 - Use to write to a file dimension on Azure Data Lake Storage Gen2.
- Amazon S3 - Use to write to a file dimension on Amazon S3.
- File - Use to write to a file dimension on HDFS or a local file system.
- JDBC - Use to write to a database table dimension.
Pipeline Configuration
You configure a slowly changing dimension pipeline differently, depending on whether it updates a dimension stored in a table or in files.
Table Dimension Pipeline
- Pipeline
- On the General tab of the pipeline properties panel, enable ludicrous mode to read only master data that is related to the change data, and thereby improve pipeline performance,
- Origins
- Configure the master origin, the JDBC Table origin, to read the master dimension data. Configure a change origin to read change data. Then, connect them to the Slowly Changing Dimension processor.
- Processor
- When both sets of data pass to the Slowly Changing Dimension processor, the processor compares change records with master records, then passes records flagged for insert or update downstream.
- Destination
- Configure the JDBC destination to write to the master dimension.
File Dimension Pipeline
For a file dimension, dimension files must be overwritten since updating a record in a file is not possible. To ensure that new dimension files contain master data as well as change data, master data must be passed through the pipeline along with change data.
A file dimension might have a few unpartitioned files or a large set of partitioned files, like a set of ORC or Parquet files. You configure a file dimension pipeline a bit differently, depending on whether files are partitioned.
- Pipeline
- For a partitioned file dimension, configure the following properties:
- Origins
- Configure the master origin, the Whole Directory origin, to read the master dimension data. Configure a change origin to read the change data. Then, connect them to the Slowly Changing Dimension processor.
- Processor
- When both sets of data pass to the Slowly Changing Dimension processor, the processor compares change records with master records, then passes records flagged for insert or update downstream.
- Destination
- Configure a dimension destination to write to the master dimension.
Partitioned File Dimension Prerequisite
To write to a partitioned file dimension, Spark must be configured to allow overwriting files within a partition. When writing to unpartitioned files, no action is needed.
To enable overwriting partitions, set the
spark.sql.sources.partitionOverwriteMode Spark configuration
property to dynamic.
You can configure the property in Spark, or you can configure the property in individual pipelines. Configure the property in Spark when you want to enable overwriting partitions for all Transformer pipelines.
To enable overwriting partitions for an individual pipeline, add an extra Spark configuration property on the Cluster tab of the pipeline properties.
Change Processing
- SCD Type - Type of slowly changing dimension, Type 1 or Type 2. For more information, see Type 1 and Type 2 Change Evaluation.
- Key Fields - One or more fields used to determine if a matching record exists in the master dimension data.
- Extra Field Mode - Action to
take when a change record includes fields that do not exist in the
corresponding master record:
- Drop - Drops extra fields from the record.
- Error - Generates an error, which stops the pipeline.
Type 1 and Type 2 Change Evaluation
- Type 1
- A Type 1 slowly changing dimension keeps only a single version of a record.
- Type 2
- A Type 2 slowly changing dimension has an active record - the most recent version of a record - and keeps previous versions of the record for historical reference.
Processor Output
By default, the Slowly Changing Dimension processor outputs change records that are flagged for insert or update.
The following properties can alter how records are processed and passed:
- Tracking Fields
- The processor adds the specified tracking fields to change records or updates existing tracking fields with the appropriate values.
- Output Full Master Data
- The processor includes all existing master data in the output. Use this option when writing to a slowly changing dimension that must be overwritten instead of updated, such as a file dimension, to ensure that the master dimension data is written along with the latest changes.
- Replace Nulls
- For Type 2 update records, the processor replaces null or missing values in the change data with the values from the latest version of the record in the master dimension data.
Tracking Fields
A tracking field is a field in a Type 2 slowly changing dimension that indicates which record is the most recent, or active, record. Type 2 dimensions can use several types of tracking fields.
Type 1 dimensions simply replace the existing record, so no earlier versions are retained. However, a Type 1 dimension can use a timestamp tracking field, such as a last-updated field, to indicate when the record was updated.
When you configure the Slowly Changing Dimension processor, you specify the tracking field name and type. You can specify as many tracking fields as appropriate.
- Version Increment
- The processor increments each version of the record and places the latest version number in a user-defined field.
- Active Flag
- The processor uses a boolean
activefield. The most recent version is flagged astrueand older versions are flagged asfalse. - As Of / Start Timestamp
- The processor places the datetime in a user-defined field each time it writes each new version. The record with the most recent datetime is the most recent record.
- End Timestamp
- The processor uses a user-defined field to indicate when a record version is no longer used. The record with no end timestamp is the most recent record.
Configuring a Slowly Changing Dimension Processor
Configure a Slowly Changing Dimension processor as part of a slowly changing dimension pipeline that updates a slowly changing dimension.
Before configuring a slowly changing dimension pipeline, consider the processing that you want to achieve. When writing to a partitioned file dimension, complete the Spark prerequisite.
For information about configuring a slowly changing dimension pipeline, see Pipeline Configuration.