Post Upgrade Tasks
In some situations, you must complete tasks within Data Collector or your Control Hub on-premises installation after you upgrade.
Update Control Hub On-Premises
By default, StreamSets Control Hub on-premises can work with registered Data Collectors from version 2.1.0.0 to the current version of Control Hub. If you use Control Hub on-premises and you upgrade registered Data Collectors to a version higher than your current version of Control Hub, you might need to modify the Data Collector version range within your Control Hub installation.
For example, if you use Control Hub on-premises version 3.8.0 and you upgrade registered Data Collectors to version 3.22.0, you must update the maximum Data Collector version that can work with Control Hub. As a best practice, configure the maximum Data Collector version to 3.99.999 to ensure that Data Collector upgrades to later minor versions, such as 3.22.1 or 3.22.2, will continue to work with Control Hub.
To modify the Data Collector version range:
- Log in to Control Hub as the default system administrator - the admin@admin user account.
- In the Navigation panel, click .
- Click the Component Version Range icon:
 .
. - Enter the maximum Data Collector version that can work with Control Hub, such as 3.99.999.
Update Pipelines using Legacy Stage Libraries
- Use a current stage library
- We strongly recommend that you upgrade your system and use a current stage
library in the pipeline:
- Upgrade the system to a more current version.
- Install the stage library for the upgraded system.
- In the pipeline, edit the stage and select the appropriate stage library.
- Install the legacy stage library
- Though not recommended, you can install the older stage libraries. For more information, see Legacy Stage Libraries.
Upgrade Enterprise Stage Libraries
When you upgrade Data Collector, you must determine whether to upgrade your Enterprise stage libraries. Releases of Enterprise stage libraries occur separately from Data Collector releases.
See Enterprise Stage Libraries for a list of available Enterprise stage libraries, the latest available versions, and links to the supported versions and the stage documentation. To view the release notes for Enterprise stage libraries, see the StreamSets Documentation page.
-
Uninstall the previous version of the Enterprise stage library.
- In Package Manager, select the installed version.
- Click the Uninstall icon.
- Restart Data Collector.
- Follow the stage documentation to install the new version of the Enterprise stage library and restart Data Collector.
Review HTTP Client Processor Pipelines
Starting with version 3.22.3, the HTTP Processor performs additional checks against the specified Batch Wait Time property. In certain cases, this change can generate errors. After upgrading from version 3.22.2 or earlier to version 3.22.3 or later, verify that pipelines that include the HTTP Client processor perform as expected.
The Batch Wait Time property defines the maximum amount of time that the processor uses to process all HTTP requests for a single record. When the processing for a record exceeds the specified batch wait time, the output records are passed to the stage for error handling.
In previous releases, the HTTP Client processor only checked the batch wait time before each HTTP request. As a result, the processor did not always notice when the processing time exceeded the batch wait time.
Starting with version 3.22.3, the HTTP Client processor checks the batch wait time before and after every request. As a result, the processor may generate more errors than in previous releases.
Also, in previous releases, the default value for Batch Wait Time was 2,000 milliseconds. Starting with version 3.22.3, the default value is 100,000 milliseconds.
For example, if you did not touch the Batch Wait Time property in a 3.22.0 pipeline, then it is increased from 2,000 to 100,000 milliseconds during the upgrade. However, if you set the property to 3000 milliseconds in a 3.22.0 pipeline, then the processor retains the 3000 millisecond batch wait time after the upgrade.
After upgrading from version 3.22.2 or earlier to version 3.22.3 or later, verify that pipelines that include the HTTP Client processor perform as expected. If you want the processor to wait for all HTTP requests to complete, increase the Batch Wait Time as needed.
Verify Elasticsearch Security
Starting with version 3.21.0, Elasticsearch stages include additional security validation. As a result, pipelines with Elasticsearch security issues that previously ran without error might fail to start after you upgrade to version 3.21.0 or later.
When this occurs, check for additional details in the error messages, then correct the security issue or stage configuration, as needed.
ELASTICSEARCH_43 - Could not connect to the server(s) <SSL/TLS error details>ELASTICSEARCH_43 - Could not connect to the server(s).
Unrecognized SSL message, plaintext connection?Note that the details of the message vary based on the originating server.
Adjust PostgreSQL CDC Pipelines or PostgreSQL Configuration
Starting with version 3.21.0, the PostgreSQL CDC Client origin includes a new Status Interval property that helps ensure that the wal2json logical decoder, which helps process changes, does not time out.
The new Status Interval origin property should be set to less than the
wal_sender_timeout property in the PostgreSQL postgresql.conf file.
Ideally, the Status Interval property should be half of the value configured for the
wal_sender_timeout property.
By default, the Status Interval property is 30 seconds. The wal2json
README.md file previously recommended setting the
wal_sender_timeout property to 2000 milliseconds, or 2 seconds. If you use these values
for both properties, the pipeline can trigger the following error:
com.streamsets.pipeline.api.StageException: JDBC_606 - Wal Sender is not activeTo avoid this issue, update one of the properties so that Status Interval is half of wal_sender_timeout.
When possible, use the default Status Interval value and the default wal_sender_timeout value of 60000 milliseconds, or 60 seconds.
Review Processing of MySQL Data (JDBC Processors)
Starting with version 3.21.0, JDBC processors convert MySQL unsigned integer data types to different Data Collector types than in earlier Data Collector versions. This change occurred for JDBC origins in an earlier version.
When you upgrade to version 3.21.0 or later, review pipelines that use JDBC processors to work with MySQL database data to ensure that downstream expressions provide the expected results.
| MySQL Data Type | Data Type Conversion Before 3.21.0 | Data Type Conversion with 3.21.0 and Later |
|---|---|---|
| Bigint Unsigned | Long | Decimal |
| Int Unsigned | Integer | Long |
| Mediumint Unsigned | Integer | Long |
| Smallint Unsigned | Short | Short |
Review Google Pub/Sub Producer Pipelines
Starting with version 3.20.0, the Google Pub/Sub Producer destination requires specifying a positive integer value for the Max Outstanding Message Count and Max Outstanding Request Bytes properties.
In earlier Data Collector versions, you could set these properties to 0 to opt out of using them. With version 3.20.0 and later, these properties must be set to a positive integer.
- Max Outstanding Message Count is set to 1000 messages
- Max Outstanding Request Bytes is set to 8000 bytes
If upgraded pipelines previously used 0 to opt out of using these properties, review the pipelines to ensure that the new default values are appropriate. Update the properties as needed.
Review JDBC Multitable Consumer Pipelines
- Multithreaded table processing
- In earlier Data Collector versions, when you use the Switch Tables batch strategy with multithreaded table processing, multiple threads can take turns processing data within a single table, caching separate result sets for the table.
- Multithreaded partition processing
- Similarly, in earlier Data Collector versions, when you use the Switch Tables batch strategy with multithreaded partition processing, multiple threads can take turns processing data within a single partition, caching separate result sets for the partition.
Review upgraded pipelines that use the Switch Table batch strategy. Depending on factors such as the number and size of the tables and partitions being processed, the change might negatively impact performance.
For example, say two threads process four tables in multithreaded table processing, and one table is much larger than the other tables. In earlier versions, using the Switch Tables batch strategy allowed multiple threads to help process the large table. With version 3.20.0 or later, only one thread can process data in one table at a time.
- If multithreaded table processing has slowed, you may have a mix of small and
large tables.
To enable large tables to be processed by more than one thread, consider using multithreaded partition processing for that table.
To enable threads to cycle through the tables more quickly, you might reduce the number of batches generated from a result set using the Batches from Result Set property.
- If multithreaded partition processing has slowed, you may have a mix of small
and large partitions.
To enable threads to cycle through the partitions more quickly, you might reduce the number of batches generated from a result set using the Batches from Result Set property.
For information about batch strategies, see Batch Strategy.
Update Oracle CDC Client Pipelines
Consider the following upgrade tasks for pipelines that contain the Oracle CDC Client origin, based on the version that you are upgrading from:
- Upgrade from versions earlier than 3.19.0
- Starting with version 3.19.0, Oracle CDC Client origins with the Parse SQL property enabled no longer generate records for SELECT_FOR_UPDATE operations.
- Upgrade from versions earlier than 3.7.0
- Starting with version 3.7.0, pipelines that use the Oracle CDC Client origin can produce some duplicate data.
Update Cluster EMR Batch Pipelines
Starting with version 3.19.0, cluster EMR batch pipelines that provision a cluster store the specified EMR version differently than in earlier versions. As a result, the EMR versions defined in earlier pipelines are not retained.
When you upgrade from a version earlier than 3.19.0, you must edit any cluster EMR batch pipeline that provisions a cluster, and define the EMR Version property.
Review Processing of MySQL Data (JDBC Origins)
Starting with version 3.17.0, JDBC origins convert MySQL unsigned integer data types to different Data Collector types than in earlier Data Collector versions.
When you upgrade to version 3.17.0 or later, review pipelines that use JDBC origins to process MySQL database data to ensure that downstream expressions provide the expected results.
| MySQL Data Type | Data Type Conversion Before 3.17.0 | Data Type Conversion with 3.17.0 and Later |
|---|---|---|
| Bigint Unsigned | Long | Decimal |
| Int Unsigned | Integer | Long |
| Mediumint Unsigned | Integer | Long |
| Smallint Unsigned | Short | Short |
Update Elasticsearch Security Properties (Optional)
Starting with version 3.17.0, Elasticsearch stages provide a User Name property and a Password property. Elasticsearch stages in previous versions pass the credentials together in a single Security Username/Password property.
When you upgrade to version 3.17.0 or later, any configuration in the Security
Username/Password properties is moved to the new User Name property, where the Security
Username/Password format, <username>:<password>, remains valid.
Though not required, you can update Elasticsearch stages to use the new User Name and Password properties.
Update Syslog Pipelines
- Use Non-Text Message Format
- Message Text
You now configure the destination to use the Text data format on the Data Format tab, just as you do with other destinations.
If pipelines created in a previous version include the Syslog destination configured to use text data, you must configure the Text data format properties on the Data Format tab after the upgrade.
JDBC Tee and JDBC Producer Cache Change
Starting with version 3.9.0, the JDBC Tee processor and the JDBC Producer destination no longer cache prepared statements when performing single-row operations. As a result, the Max Cache Size Per Batch property has been removed from both stages.
In previous versions when you enabled the stage to perform single-row operations, you could configure the Max Cache Size Per Batch property to specify the maximum number of prepared statements to store in the cache.
Pipeline Export
Starting with version 3.8.0, Data Collector has changed the behavior of the pipeline Export option. Data Collector now strips all plain text credentials from exported pipelines. Previously, Data Collector included plain text credentials in exported pipelines.
To use the previous behavior and include credentials in the export, choose the new Export with Plain Text Credentials option when exporting a pipeline.
Update TCP Server Pipelines
Starting with version 3.7.2, the TCP Server origin has changed the valid values for the Read Timeout property. The property now allows a minimum of 1 second and a maximum of 3,600 seconds.
In previous versions, the Read Timeout property had no maximum value and could be set to 0 to keep the connection open regardless of whether the origin read any data.
If pipelines created in a previous version have the Read Timeout property set to a value less than 1 or greater than 3,600, the upgrade process sets the property to the maximum value of 3,600 seconds. If necessary, update the Read Timeout property as needed after the upgrade.
Update Cluster Pipelines
Starting with version 3.7.0, Data Collector now requires that the Java temporary directory on the gateway node in the cluster is writable.
The Java temporary directory is specified by the Java system property
java.io.tmpdir. On UNIX, the default value of this property is
typically /tmp and is writable.
Previous Data Collector versions did not have this requirement. Before running upgraded cluster pipelines, verify that the Java temporary directory on the gateway node is writable.
Update Kafka Consumer or Kafka Multitopic Consumer Pipelines
Starting with version 3.7.0, Data Collector no
longer uses the auto.offset.reset value set in the Kafka Configuration
property to determine the initial offset for the Kafka Consumer or Kafka Multitopic
Consumer origin. Instead, Data Collector
uses the new Auto Offset Reset property to determine the initial offset. With the
default setting of the new property, the origin reads all existing messages in a topic.
In previous versions, the origin read only new messages by default. Because running a
pipeline sets an offset value, configuration of the initial offset only affects
pipelines that have never run.
- On the Kafka tab for the origin, set the value of the
Auto Offset Reset property:
- Earliest - Select to have the origin read messages starting with the first message in the topic (same behavior as configuring auto.offset.reset to earliest in previous versions of Data Collector).
- Latest - Select to have the origin read messages starting with the last message in the topic (same behavior as not configuring auto.offset.reset in previous versions of Data Collector).
- Timestamp - Select to have the origin read messages starting with messages at a particular timestamp, which you specify in the Auto Offset Reset Timestamp property.
- If configured in the Kafka Configuration property, delete the auto.offset.reset property.
Update JDBC Pipelines
Starting with version 3.5.0, Data Collector requires the maximum lifetime for a connection to be at least 30 minutes in stages that use a JDBC connection. Data Collector does not validate stages with lower non-zero values configured.
If you upgrade pipelines that include a stage that uses a JDBC connection, update the stage to set the maximum lifetime for a connection to be at least 30 minutes.
Update Spark Executor with Databricks Pipelines
Starting with version 3.5.0, Data Collector introduces a new Databricks Job Launcher executor and has removed the ability to use the Spark executor with Databricks.
If you upgrade pipelines that include the Spark executor with Databricks, you must update the pipeline to use the Databricks Job Launcher executor after you upgrade.
Update Pipelines to Use Spark 2.1 or Later
Starting with version 3.3.0, Data Collector removes support for Spark 1.x and introduces cluster streaming mode with support for Kafka security features such as SSL/TLS and Kerberos authentication using Spark 2.1 or later and Kafka 0.10.0.0 or later. For more information about these changes, see Upgrade to Spark 2.1 or Later.
After upgrading the Cloudera CDH distribution, Hortonworks Hadoop distribution, or Kafka system to the required version and then upgrading Data Collector, you must update pipelines to use Spark 2.1 or later. Pipelines that use the earlier systems will not run until you perform these tasks:
- Install the stage library for the upgraded system.
- In the pipeline, edit the stage and select the appropriate stage library.
- If the pipeline includes a Spark Evaluator processor and the Spark application was
previously built with Spark 2.0 or earlier, rebuild it with Spark 2.1.
Or if you used Scala to write the custom Spark class, and the application was compiled with Scala 2.10, recompile it with Scala 2.11.
- If the pipeline includes a Spark executor and the Spark application was previously built with Spark 2.0 or earlier, rebuild it with Spark 2.1 and Scala 2.11.
Update Value Replacer Pipelines
Starting with version 3.1.0.0, Data Collector introduces a new Field Replacer processor and has deprecated the Value Replacer processor.
The Field Replacer processor lets you define more complex conditions to replace values. For example, unlike the Value Replacer, the Field Replacer can replace values that fall within a specified range.
You can continue to use the deprecated Value Replacer processor in pipelines. However, the processor will be removed in a future release - so we recommend that you update pipelines to use the Field Replacer as soon as possible.
To update your pipelines, replace the Value Replacer processor with the Field Replacer processor. The Field Replacer replaces values in fields with nulls or with new values. In the Field Replacer, use field path expressions to replace values based on a condition.
For example, let's say that your Value Replacer processor is configured to replace null values in the product_id field with "NA" and to replace the "0289" store ID with "0132" as follows:
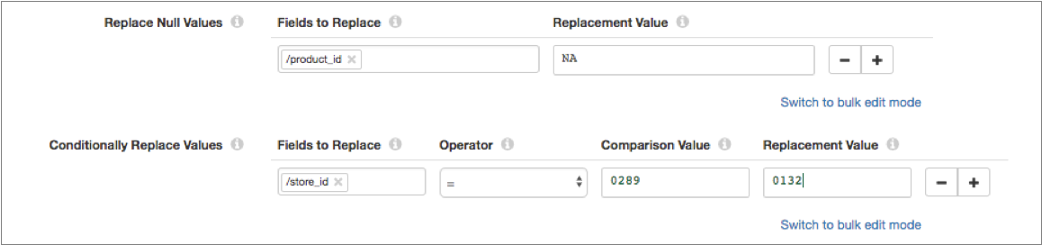
In the Field Replacer processor, you can configure the same replacements using field path expressions as follows:

Update Einstein Analytics Pipelines
Starting with version 3.1.0.0, the Einstein Analytics destination introduces a new append operation that lets you combine data into a single dataset. Configuring the destination to use dataflows to combine data into a single dataset has been deprecated.
You can continue to configure the destination to use dataflows. However, dataflows will be removed in a future release - so we recommend that you update pipelines to use the append operation as soon as possible.
Disable Cloudera Navigator Integration
Starting with version 3.0.0.0, the beta version of Cloudera Navigator integration is no longer available with Data Collector. Cloudera Navigator integration now requires a paid subscription. For more information about purchasing Cloudera Navigator integration, contact StreamSets.
When upgrading from a Data Collector version with Cloudera Navigator integration enabled to version 3.0.0.0 without a paid subscription, perform the following post-upgrade task:
- lineage.publishers
- lineage.publisher.navigator.def
- All other properties with the lineage.publisher.navigator prefix
JDBC Multitable Consumer Query Interval Change
Starting with version 3.0.0.0, the Query Interval property is replaced by the new Queries per Second property.
Queries per Second = Number of Threads / Query Interval (in seconds)The upgrade would occur the same way if Query Interval were set to 15.
Pipelines with a Query Interval configured to use other units of time, such as ${.1 *MINUTES}, or configured with a different expression format, such as ${SECONDS * 5}, are upgraded to use the default for Queries per Second, which is 10. This means the pipeline will run a maximum of 10 queries per second. The fact that these expressions are not upgraded correctly is noted in the Data Collector log.
If necessary, update the Queries per Second property as needed after the upgrade.
Update JDBC Query Consumer Pipelines used for SQL Server CDC Data
Starting with version 3.0.0.0, the Microsoft SQL Server CDC functionality in the JDBC Query Consumer origin has been deprecated and will be removed in a future release.
- To read data from Microsoft SQL Server CDC tables, use the SQL Server CDC Client origin.
- To read data from Microsoft SQL Server change tracking tables, use the SQL Server Change Tracking origin.
Update MongoDB Destination Upsert Pipelines
Starting with version 3.0.0.0, the MongoDB destination supports the replace and update operation codes, and no longer supports the upsert operation code. You can use a new Upsert flag in conjunction with Replace and Update.
After upgrading from a version earlier than 3.0.0.0, update the pipeline as needed to ensure that records passed to the destination do not use the upsert operation code (sdc.operation.type = 4). Records that use the upsert operation code will be sent to error.
In previous releases, records flagged for upsert were treated in the MongoDB system as Replace operations with the Upsert flag set.
- Configure the pipeline to use the Replace operation code.
Make sure that the sdc.operation.type is set to 7 for Replace instead of 4 for Upsert.
- In the MongoDB destination, enable the new Upsert property.
Time Zones in Stages
Starting with version 3.0.0.0, time zones have been organized and updated to use JDK 8 names. This should make it easier to select time zones in stage properties.
In the rare case that an upgraded pipeline uses a format not supported by JDK 8, edit the pipeline to select a compatible time zone.
Update Kudu Pipelines
Consider the following upgrade tasks for Kudu pipelines, based on the version that you are upgrading from:
- Upgrade from versions earlier than 3.0.0.0
- Starting with version 3.0.0.0, if the destination receives a change data capture log from the following source systems, you must specify the source system so that the destination can determine the format of the log: Microsoft SQL Server, Oracle CDC Client, MySQL Binary Log, or MongoDB Oplog.
- Upgrade from versions earlier than 2.2.0.0
- Starting with version 2.2.0.0, Data Collector provides support for Apache Kudu version 1.0.x and no longer supports earlier
Kudu versions. To upgrade pipelines that contain a Kudu destination from Data Collector versions earlier than 2.2.0.0, upgrade your Kudu cluster and then add a stage
alias for the earlier Kudu version to the Data Collector configuration file,
$SDC_CONF/sdc.properties.
Update JDBC Multitable Consumer Pipelines
Starting with version 2.7.1.1, the JDBC Multitable Consumer origin can now read from views in addition to tables. The origin now reads from all tables and all views that are included in the defined table configurations.
When upgrading pipelines that contain a JDBC Multitable Consumer origin from Data Collector versions earlier than 2.7.1.1, review the table configurations to determine if any views are included. If a table configuration includes views that you do not want to read, simply exclude them from the configuration.
Update Vault Pipelines
Starting with version 2.7.0.0, Data Collector introduces a credential store API and credential expression language functions to access Hashicorp Vault secrets.
In addition, the Data Collector Vault integration now relies on Vault's App Role authentication backend.
Previously, Data Collector used Vault functions to access Vault secrets and relied on Vault's App ID authentication backend. StreamSets has deprecated the Vault functions, and Hashicorp has deprecated the App ID authentication backend.
After upgrading, update pipelines that use Vault functions in one of the following ways:
- Use the new credential store expression language functions (recommended)
- To use the new credential functions, install the Vault credential store stage library and define the configuration properties used to connect to Vault. Then, update each upgraded pipeline that includes stages using Vault functions to use the new credential functions to retrieve the credential values.
- Continue to use the deprecated Vault functions
- You can continue to use the deprecated Vault functions in pipelines. However, the functions will be removed in a future release - so we recommend that you use the credential functions as soon as possible.
Configure JDBC Producer Schema Names
Starting with Data Collector version 2.5.0.0, you can use a Schema Name property to specify the database or schema name. In previous releases, you specified the database or schema name in the Table Name property.
Upgrading from a previous release does not require changing any existing configuration at this time. But we recommend using the new Schema Name property, since the ability to specify a database or schema name with the table name might be deprecated in the future.
Evaluate Precondition Error Handling
Starting with Data Collector version 2.5.0.0, precondition error handling has changed.
The Precondition stage property allows you to define conditions that must be met for a record to enter the stage. Previously, records that did not meet all specified preconditions were passed to the pipeline for error handling. That is, the records were processed based on the Error Records pipeline property.
With version 2.5.0.0, records that do not meet the specified preconditions are handled by the error handling configured for the stage. Stage error handling occurs based on the On Record Error property on the General tab of the stage.
Review pipelines that use preconditions to verify that this change does not adversely affect the behavior of the pipelines.
Authentication for Docker Image
Starting with Data Collector
version 2.4.1.0, the Docker image now uses the form type of file-based authentication by
default. As a result, you must use a Data Collector
user account to log in to the Data Collector. If
you haven't set up custom user accounts, you can use the admin account shipped with the
Data Collector. The default login is: admin / admin.
Earlier versions of the Docker image used no authentication.
Configure Pipeline Permissions
Data Collector version 2.4.0.0 is designed for multitenancy and enables you to share and grant permissions on pipelines. Permissions determine the access level that users and groups have on pipelines.
In earlier versions of Data Collector without pipeline permissions, pipeline access is determined by roles. For example, any user with the Creator role could edit any pipeline.
In version 2.4.0.0, roles are augmented with pipeline permissions. In addition to having the necessary role, users must also have the appropriate permissions to perform pipeline tasks.
For example, to edit a pipeline in 2.4.0.0, a user with the Creator role must also have read and write permission on the pipeline. Without write permission, the user cannot edit the pipeline. Without read permission, the user cannot see the pipeline at all. It does not display in the list of available pipelines.
In Data Collector version 2.5.0.0, pipeline permissions are disabled by default. To enable pipeline permissions, set the pipeline.access.control.enabled property to true in the Data Collector configuration file.
For more information about roles and permissions, see Roles and Permissions. For details about configuring pipeline permissions, see Sharing Pipelines.
Update Elasticsearch Pipelines
Data Collector version 2.3.0.0 includes an enhanced Elasticsearch destination that uses the Elasticsearch HTTP API. To upgrade pipelines that use the Elasticsearch destination from Data Collector versions earlier than 2.3.0.0, you must review the value of the Default Operation property.
Review all upgraded Elasticsearch destinations to ensure that the Default Operation property is set to the correct operation. Upgraded Elasticsearch destinations have the Default Operation property set based on the configuration for the Enable Upsert property:
- With upsert enabled, the default operation is set to INDEX.
- With upsert not enabled, the default operation is set to CREATE which requires a DocumentId.