MapR Event Store
The MapR Event Store origin reads data from one or more topics in MapR Streams. All messages in a batch must use the same schema. MapR Streams uses Kafka APIs to process messages. Use the origin only in pipelines that run on MapR distributions of Hadoop YARN clusters.
MapR is now HPE Ezmeral Data Fabric. This documentation uses "MapR" to refer to both MapR and HPE Ezmeral Data Fabric.
When configuring the MapR Event Store origin, you specify the topics the origin reads, and where to start reading each topic. The origin can start processing from the first message, the last message, or a specified offset.
You specify the maximum number of messages to read from any partition in each batch. You can define additional configuration properties to pass to MapR Streams. You can configure the origin to include Kafka message keys in records.
You select the data format of the data and configure related properties. When processing delimited or JSON data, you can define a custom schema for reading the data and configure related properties.
You can configure the origin to load data only once and cache the data for reuse throughout the pipeline run. Or, you can configure the origin to cache each batch of data so the data can be passed to multiple downstream batches efficiently. You can also configure the origin to skip tracking offsets.
Partitioning
Spark runs a Transformer pipeline just as it runs any other application, splitting the data into partitions and performing operations on the partitions in parallel. When the pipeline starts processing a new batch, Spark determines how to split pipeline data into initial partitions based on the origins in the pipeline.
For a MapR Event Store origin, Spark determines the partitioning based on the number of partitions in the topics being read. For example, if a MapR Event Store origin is configured to read from 10 topics that each have 5 partitions, Spark creates a total of 50 partitions to read from MapR Streams.
Spark uses these partitions while the pipeline processes the batch unless a processor causes Spark to shuffle the data. To change the partitioning in the pipeline, use the Repartition processor.
Topics and Offsets
The MapR Event Store origin reads messages from one or more topics that you specify. You define the starting offset to indicate the first message to read in each partition of a topic.
- Earliest
- The origin reads all available messages, starting with the first message in each partition of each topic.
- Latest
- The origin reads the last message in each partition of each topic and any subsequent messages added to those topics after the pipeline starts.
- Specific offsets
- The origin reads messages starting from a specified offset for each partition in each topic. If an offset is not specified for a partition in a topic, the origin returns an error.
When reading the last message in a batch, the origin saves the offset from that message. In the subsequent batch, the origin starts reading from the next message.
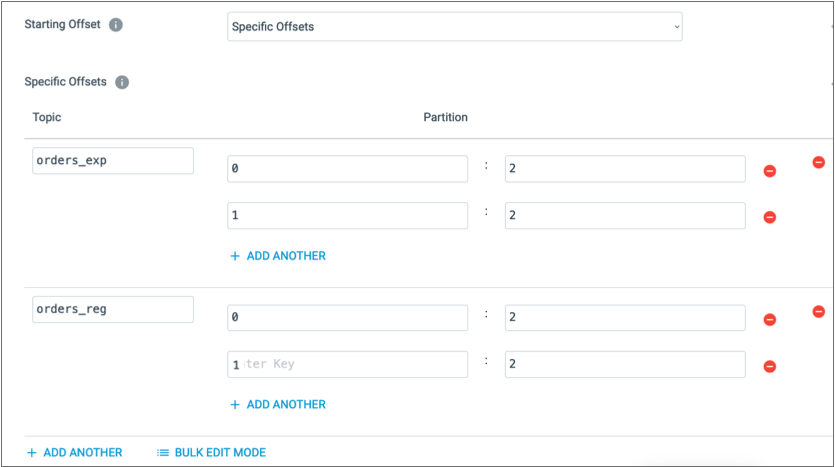
For example, suppose the orders_exp and
orders_reg topics have two partitions, 0 and
1. To have the origin read from the partitions starting with
the third message, which has an offset of 2, configure the origin
as follows:
Data Formats
The MapR Event Store origin generates records based on the specified data format.
- Avro
- The origin generates a record for every message. Note: To use the Avro data format, Apache Spark version 2.4 or later must be installed on the Transformer machine and on each node in the cluster.You can use one of the following methods to specify the location of the Avro schema definition:
- In Pipeline Configuration - Use the schema defined in the stage properties.
- Confluent Schema Registry - Retrieve the schema from Confluent Schema Registry. Confluent Schema Registry is a distributed storage layer for Avro schemas. You specify the URL to Confluent Schema Registry and whether to look up the schema by the schema ID or subject.
- Delimited
- The origin generates a record for every message. You can specify a custom delimiter, quote, and escape character used in the data.
- JSON
- The origin generates a record for every message.
- Text
- The origin generates a record for every message.
Configuring a MapR Event Store Origin
Configure a MapR Event Store origin to read data from MapR Streams. Use the origin only in pipelines that run on MapR distributions of Hadoop YARN clusters.