PostgreSQL CDC Client
Supported pipeline types:
|
You might use this origin to perform database replication. You can use a separate pipeline with the JDBC Query Consumer or JDBC Multitable Consumer origin to read existing data. Then start a pipeline with the PostgreSQL CDC Client origin to process subsequent changes.
The PostgreSQL CDC Client generates a single record from each transaction. Since each transaction can include multiple CRUD operations, the PostgreSQL CDC Client origin can also include multiple operations in a record.
As a result, the origin does not write the CRUD
operations to the sdc.operation.type record header
attribute. Depending on your use case, you might use a scripting processor
to convert the records as needed. Or, you might use a Field Pivoter and
other processors to separate the data to create a record for each
operation. For an overview of Data Collector
changed data processing and a list of CRUD-enabled destinations, see Processing Changed Data.
When you configure the PostgreSQL CDC Client, you configure the change capture details, such as the schema and tables to read from, the initial change to use, and the operations to include. You can also use a connection to configure the origin.
You define the name for the replication slot to be used, and specify whether to remove replication slots on close. You can also specify the behavior when the origin encounters an unsupported data type and include the data for those fields in the record as unparsed strings. When the source database has high-precision timestamps, you can configure the origin to write string values rather than datetime values to maintain the precision.
To determine how the origin connects to the database, you specify connection information, a query interval, number of retries, and any custom JDBC configuration properties that you need. You can configure advanced connection properties.
You can also configure the origin to use a secure connection to the database server using SSL/TLS encryption.
Before you configure the origin, you must complete a prerequisite.
JDBC Driver
When connecting to a PostgreSQL database, you do not need to install a JDBC driver. Data Collector includes the JDBC driver required for PostgreSQL.
PostgreSQL Prerequisite
To enable the PostgreSQL CDC Client origin to read Write-Ahead Logging (WAL) changed data capture information, you must install the wal2json logical decoder. Install wal2json on every PostgreSQL instance being monitored for changes.
StreamSets provides the wal2json logical decoder on GitHub. To install the wal2json, follow the instructions in the "Build and Install" section of the README.md file.
Then, follow the configuration instructions in the "Configuration" section of the README.md file.
Schema, Table Name, and Exclusion Patterns
When you configure the PostgreSQL CDC Client origin, you specify the tables with the change capture data that you want to process. To specify the tables, you define the schema, a table name pattern, and an optional exclusion pattern.
When defining the schema and table name pattern, you can use SQL LIKE syntax to define a set of tables within a schema or across multiple schemas. For more information about valid patterns for the SQL LIKE syntax, see the PostgreSQL documentation.
When needed, you can also use a regular expression as an exclusion pattern to exclude a subset of tables from the larger set.
- Schema:
sales - Table Name Pattern:
SALES% - Exclusion Pattern:
SALES.*-.
Initial Change
The initial change is the point in the Write-Ahead Logging (WAL) data where you want to start processing. When you start the pipeline for the first time, the origin starts processing from the specified initial change. The origin only uses the specified initial change again when you reset the origin.
Note that PostgreSQL CDC Client processes only change capture data. If you need existing data, you might use a JDBC Query Consumer or a JDBC Multitable Consumer in a separate pipeline to read table data before you start a PostgreSQL CDC Client pipeline.
- From the latest change
- The origin processes all changes that occur after you start the pipeline.
- From a specified datetime
- The origin processes all changes that occurred at the specified datetime and
later. Use the following format:
DD-MM-YYYY HH24:MI:SS. - From a specified log sequence number (LSN)
- The origin processes all changes that occurred in the specified LSN and later. When using the specified LSN, the origin starts processing with the timestamp associated with the LSN. If the LSN cannot be found in the WAL data, the origin continues reading from the next higher LSN that is available.
Example
You want to process all existing data in the Sales schema and then capture changed data, writing all data to Google Bigtable. To do this, you create two pipelines.
To read the existing data from the schema, you use a pipeline with the JDBC Multitable Consumer and Google Bigtable destination as follows:
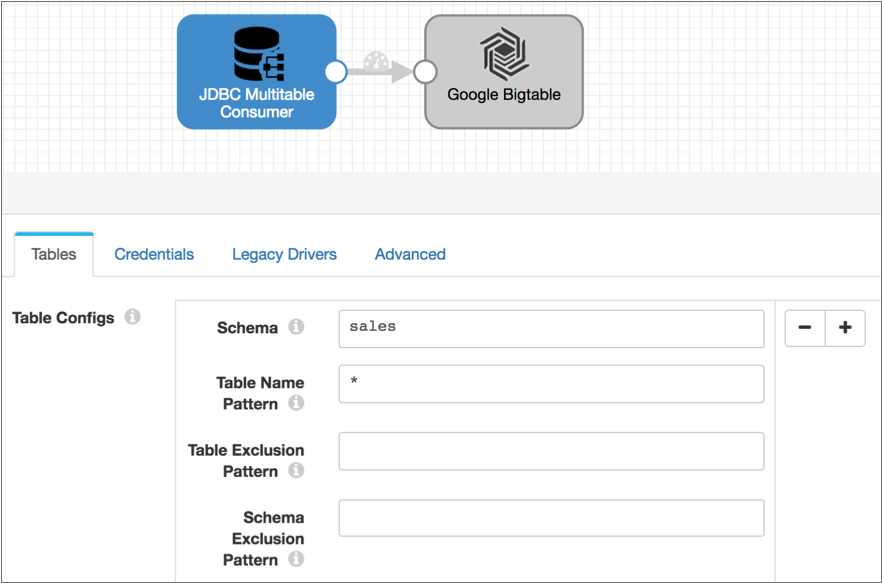
Once all existing data is read, you stop the JDBC Multitable Consumer pipeline and start the following PostgreSQL CDC Client pipeline. This pipeline is configured to pick up changes that occur after you start the pipeline, but if you wanted to prevent any chance of data loss, you could configure the initial change for an exact datetime or earlier LSN:
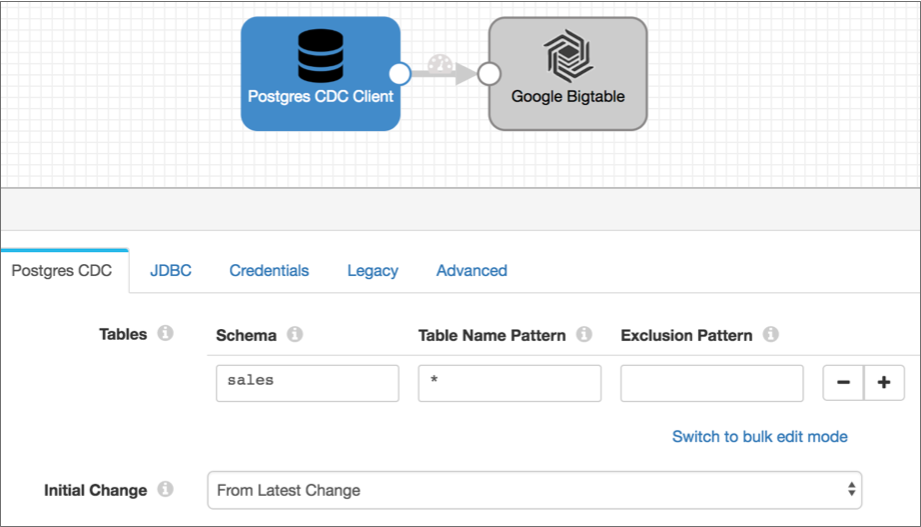
SSL/TLS Encryption
You can secure the connection to the PostgreSQL database by configuring the origin to use SSL/TLS encryption.
Before configuring the origin to use SSL/TLS encryption, verify that the database is correctly configured to use SSL/TLS. For more information, see the PostgreSQL documentation.
Define one of the following SSL/TLS modes that the origin uses to connect to PostgreSQL:
- Disabled
- The stage does not establish an SSL/TLS connection.
- Required
- The stage establishes an SSL/TLS connection without any verification. The stage trusts the certificate and host name of the PostgreSQL server.
- Verify CA
- The stage establishes an SSL/TLS connection only after successfully verifying the certificate of the PostgreSQL server.
- Verify Full
- The stage establishes an SSL/TLS connection only after successfully verifying the certificate and host name of the PostgreSQL server.
-----BEGIN CERTIFICATE REQUEST-----
MIIB9TCCAWACAQAwgbgxGTAXBgNVHJoMEFF1b1ZlZGwzIEkpbWl0ZWLxHLAaBgNV
......
98TwDIK/39WEB/V607As+KoYajQL9drorw==
-----END CERTIFICATE REQUEST-----For more information about the SSL/TLS modes available with PostgreSQL, see the PostgreSQL documentation.
Generated Record
The PostgreSQL CDC Client generates a single record from each transaction. Since each transaction can include multiple CRUD operations, the PostgreSQL CDC Client origin can also include multiple operations in a record.
As a result, the origin does not write the CRUD
operations to the sdc.operation.type record header
attribute. Depending on your use case, you might use a scripting processor
to convert the records as needed. Or, you might use a Field Pivoter and
other processors to separate the data to create a record for each
operation.
The PostgreSQL CDC Client origin records include the following fields:
| Field Name | Description |
|---|---|
| xid | Transaction ID. |
| nextlsn | Next Logical Sequence Number (LSN). |
| timestamp | Timestamp with sub-second granularity, including the time zone offset from UTC. |
| change | A list field that includes the following details about each data
change:
|
Sample Record
xid includes six
operations:{
"xid": 598,
"nextlsn": "0/16751E8",
"timestamp": "2018-07-13 13:24:44.152109-07",
"change": [
{
"kind": "update",
"schema": "public",
"table": "table1",
"columnnames": [
"id",
"value"
],
"columntypes": [
"integer",
"character(33)"
],
"columnvalues": [
1,
"a"
],
"oldkeys": {
"keynames": [
"value"
],
"keytypes": [
"character(33)"
],
"keyvalues": [
"a"
]
}
},
{
"kind": "update",
"schema": "public",
"table": "table1",
"columnnames": [
"id",
"value"
],
"columntypes": [
"integer",
"character(33)"
],
"columnvalues": [
2,
"b"
],
"oldkeys": {
"keynames": [
"value"
],
"keytypes": [
"character(33)"
],
"keyvalues": [
"b"
]
}
},
{
"kind": "update",
"schema": "public",
"table": "table1",
"columnnames": [
"id",
"value"
],
"columntypes": [
"integer",
"character(33)"
],
"columnvalues": [
3,
"c"
],
"oldkeys": {
"keynames": [
"value"
],
"keytypes": [
"character(33)"
],
"keyvalues": [
"c"
]
}
},
{
"kind": "update",
"schema": "public",
"table": "table2",
"columnnames": [
"id",
"name"
],
"columntypes": [
"integer",
"character varying(255)"
],
"columnvalues": [
1,
"a"
],
"oldkeys": {
"keynames": [
"id"
],
"keytypes": [
"integer"
],
"keyvalues": [
1
]
}
},
{
"kind": "update",
"schema": "public",
"table": "table2",
"columnnames": [
"id",
"name"
],
"columntypes": [
"integer",
"character varying(255)"
],
"columnvalues": [
2,
"b"
],
"oldkeys": {
"keynames": [
"id"
],
"keytypes": [
"integer"
],
"keyvalues": [
2
]
}
},
{
"kind": "update",
"schema": "public",
"table": "table2",
"columnnames": [
"id",
"name"
],
"columntypes": [
"integer",
"character varying(255)"
],
"columnvalues": [
3,
"c"
],
"oldkeys": {
"keynames": [
"id"
],
"keytypes": [
"integer"
],
"keyvalues": [
3
]
}
}
]
}
CDC Header Attributes
| CDC Header Attribute | Description |
|---|---|
| postgres.cdc.lsn | Logical Sequence Number of this record. |
| postgres.cdc.xid | Transaction ID. |
| postgres.cdc.timestamp | Timestamp of transaction. |
Configuring a PostgreSQL CDC Client Origin
Configure a PostgreSQL CDC Client origin to process WAL change data capture data from a PostgreSQL database.
Before you configure the origin, complete the prerequisite task.